Using Machine Learning to Predict Urban Development
This post shows a published study the author conducted while working at Skidmore, Owings and Merill. The author developed with his team a complete workflow of constructing and applying several Machine Learning models to analyze historical development data in the City of San Francisco. The project predicts potential real estate development sites in San Francisco based on historic trends, property characteristics and geospatial proximities.
Project Background
In this project, I utilized Machine Learning algorithms to predict the future development potentials across the City of San Francisco, CA. The model takes into consideration a wide range of parcel information and geospatial features from the City’s publicly available development pipeline data in the past 10 years.
Where are the next real estate developments likely to happen?
The Wealth of Data
Representative features about parcels were selected, including parcel size, year of structure built, assessed values, zoning regulations, building square footages, etc. These features were common factors to consider when a real estate developer investigates sites for potential development. These form the basis of the parcel data set that the Machine Learning model will further train on.
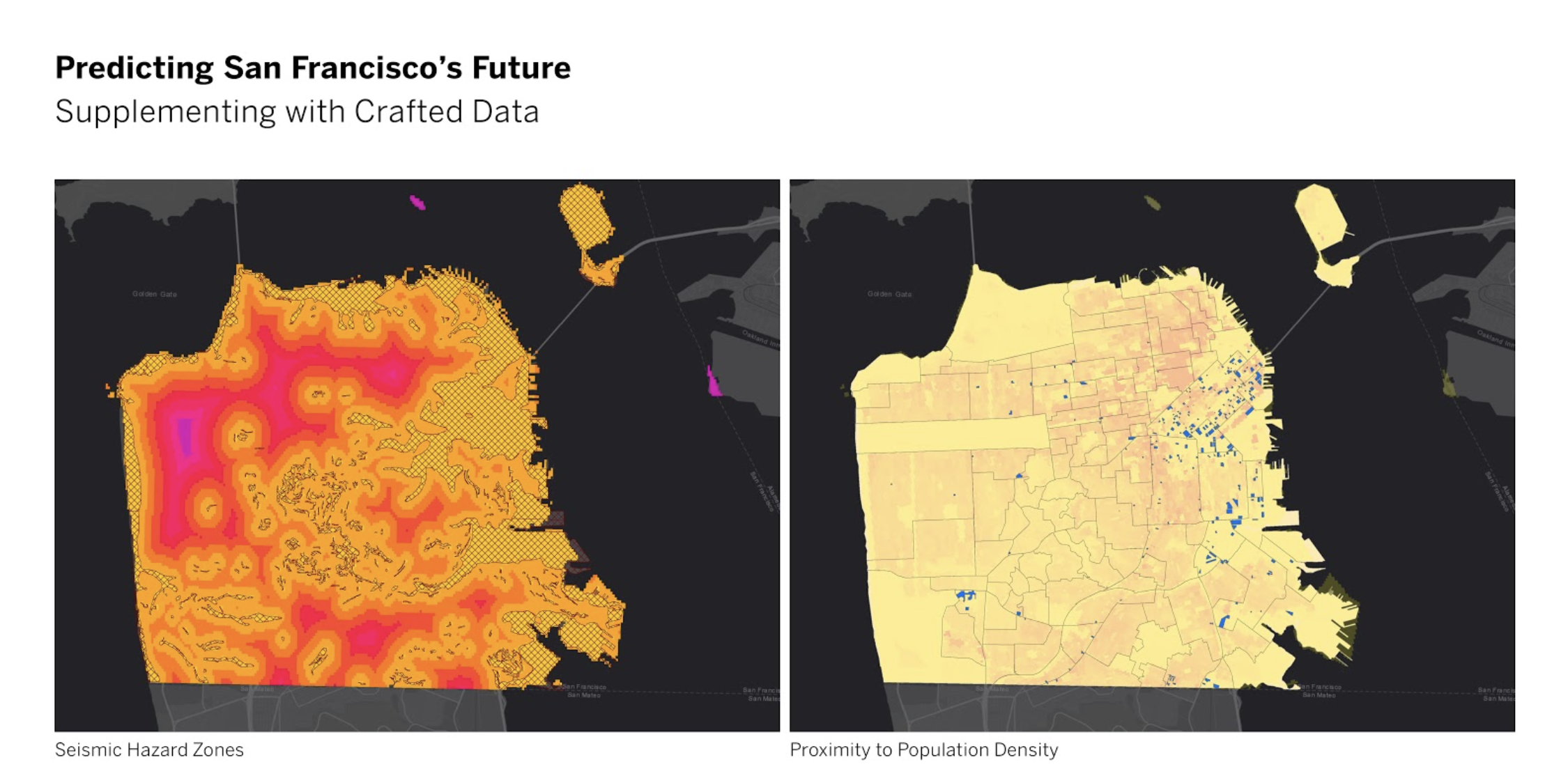
The Geospatial Layer of Things
Then, a series of geospatial analyses were conducted to generate parcel-based accessibility values to different types of urban amenities (transit stops, parks, schools, retails, etc.). These geospatial features were then added to the main parcel dataset as additional geospatial features.
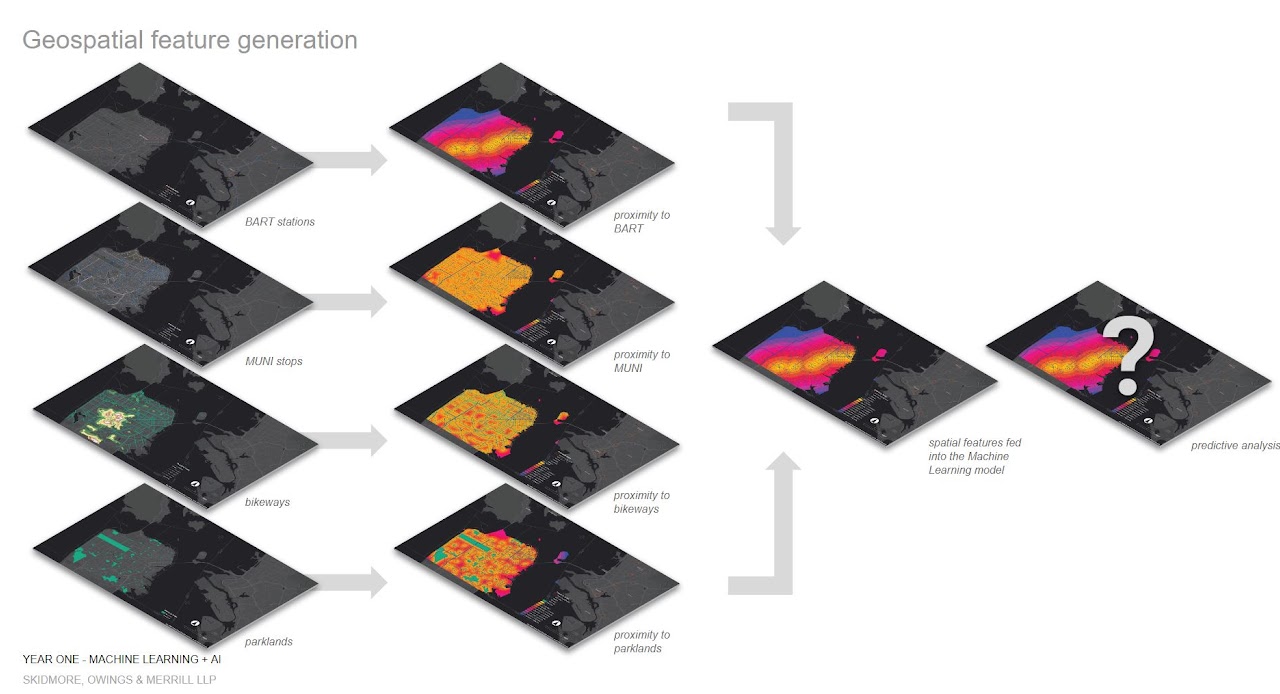
Below are some study maps visualizing the geospatial analyses performed to measure spatial proximity to various amenities that are important to real estate development.
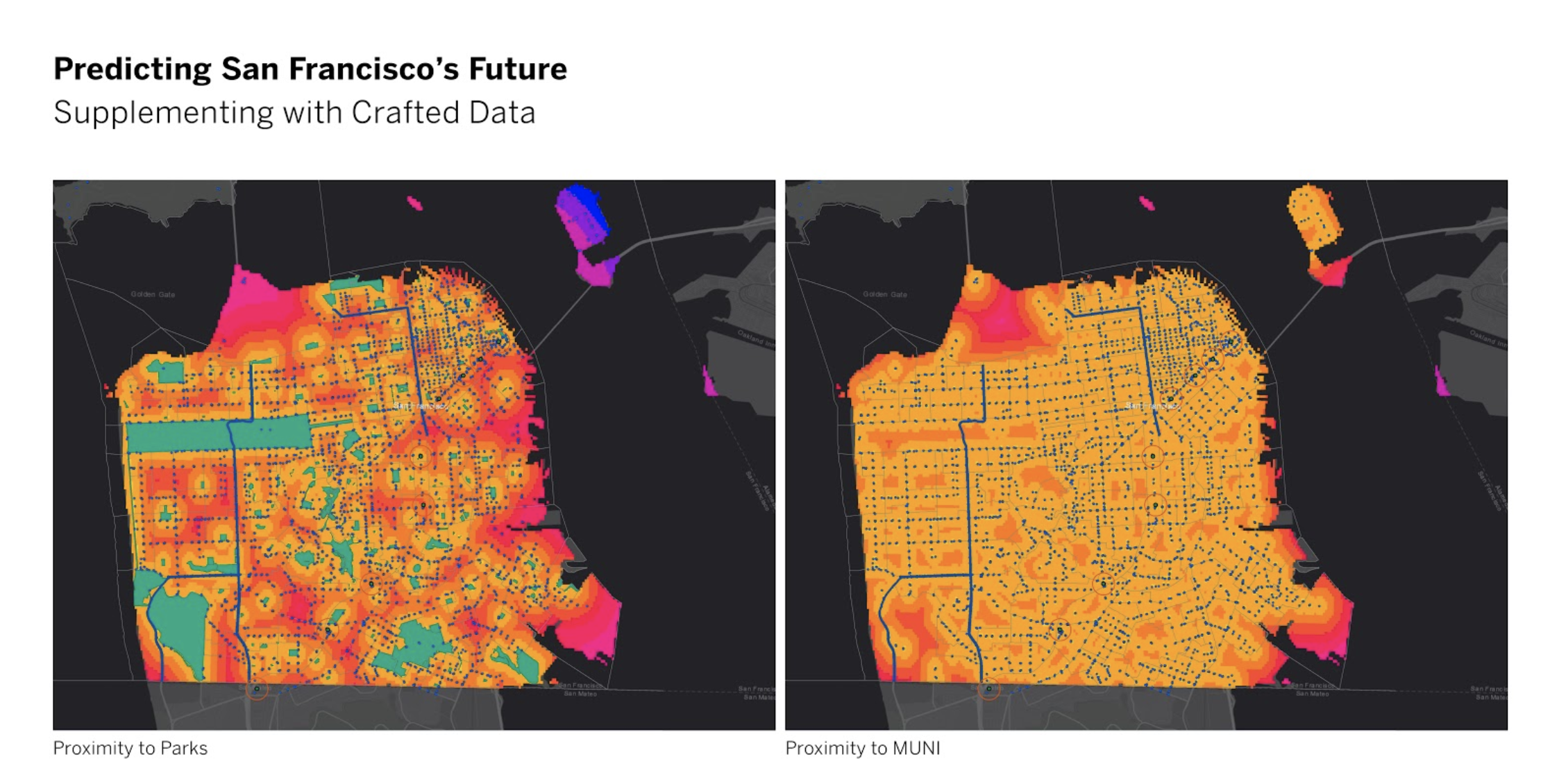
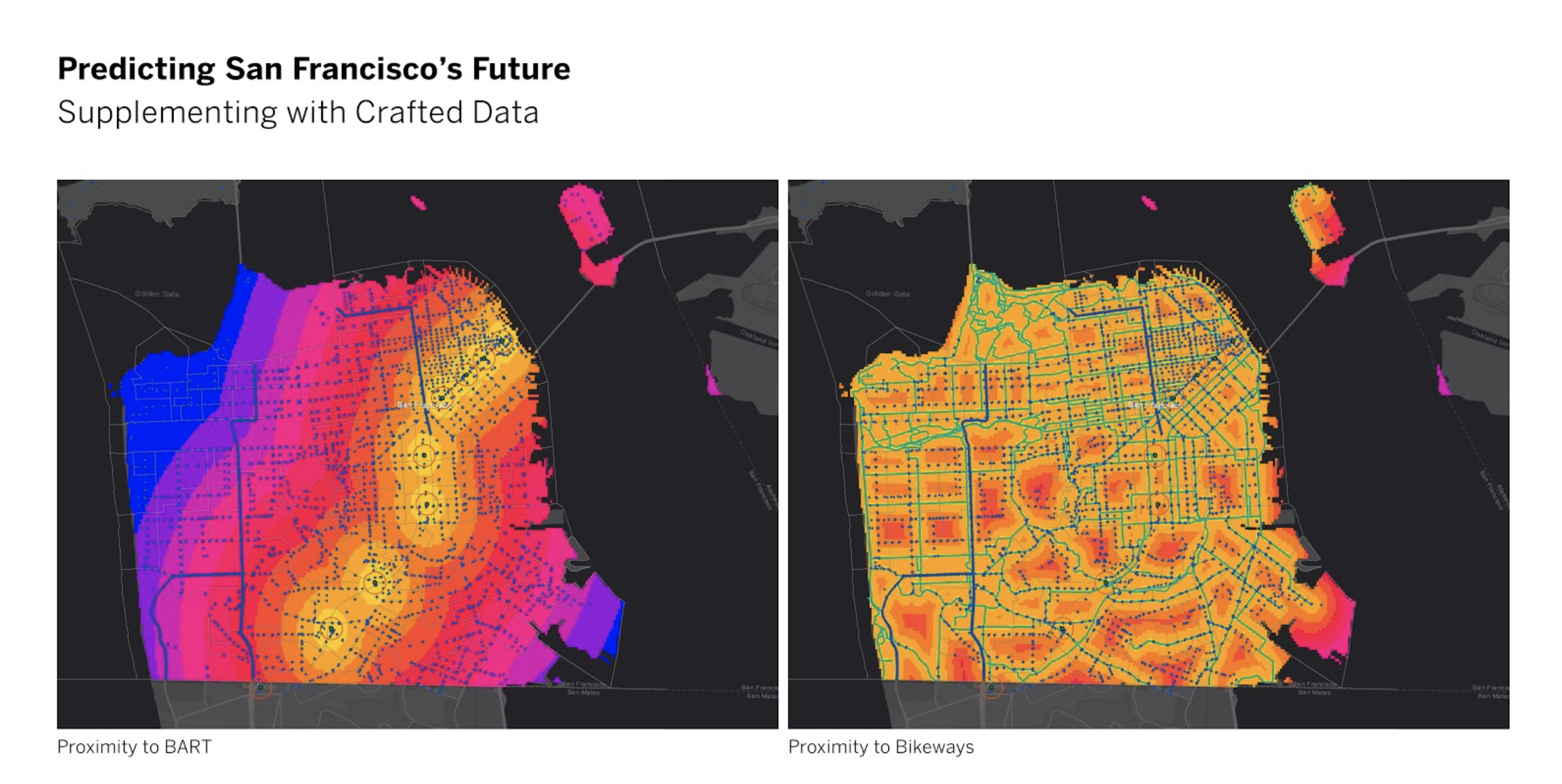
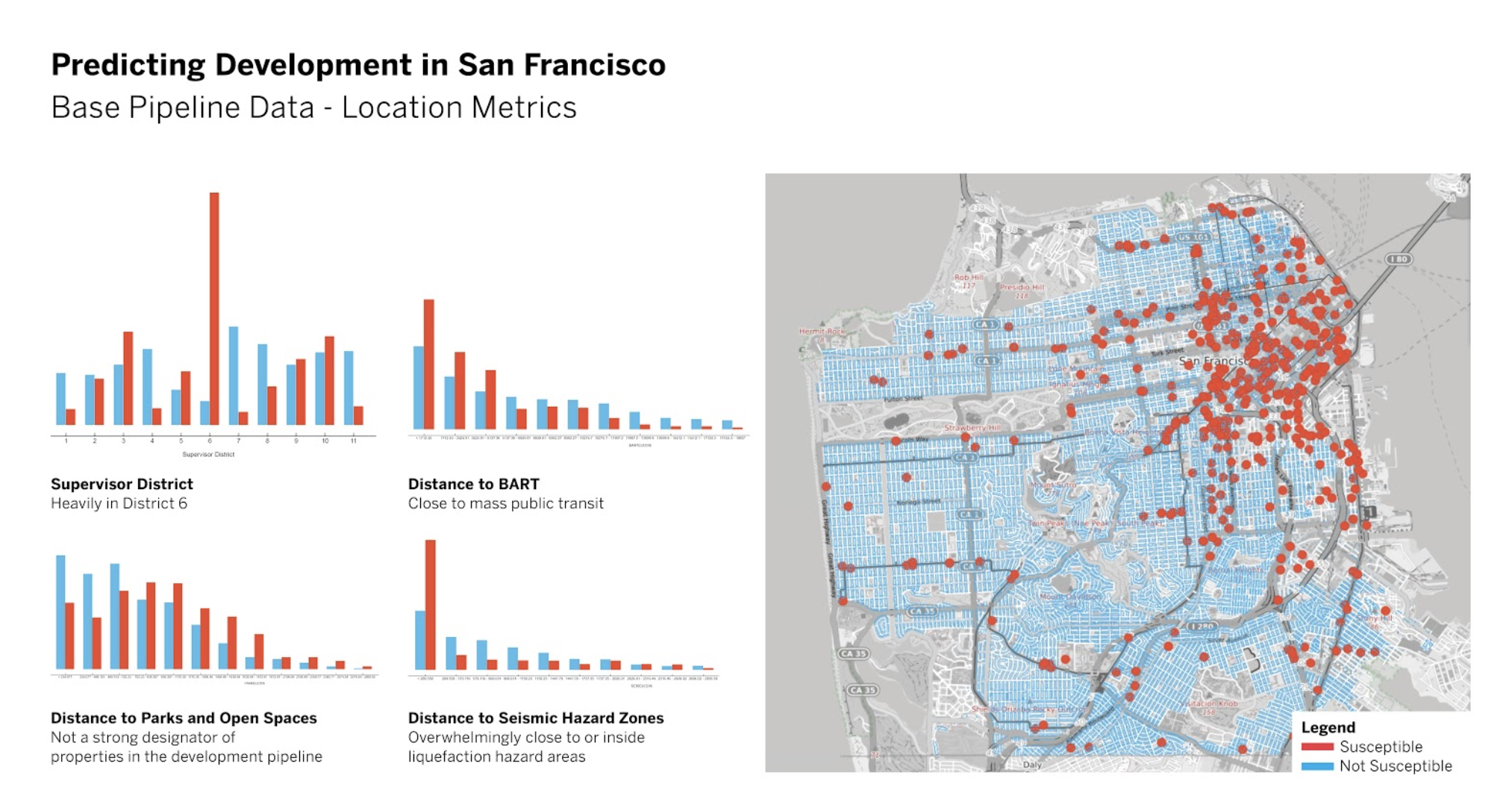
All parcels that have been included in the development pipeline over the past 10 years were marked as “Susceptible”, and all the other parcels were marked as “Not Susceptible”. A first look at this existing parcel data reveals some interesting patterns, for example, parcels located near BART stations are more likely to appear on the development pipeline than far away, yet parcels with mid-distance to parks and open spaces made the most frequent appearances on the development pipeline.
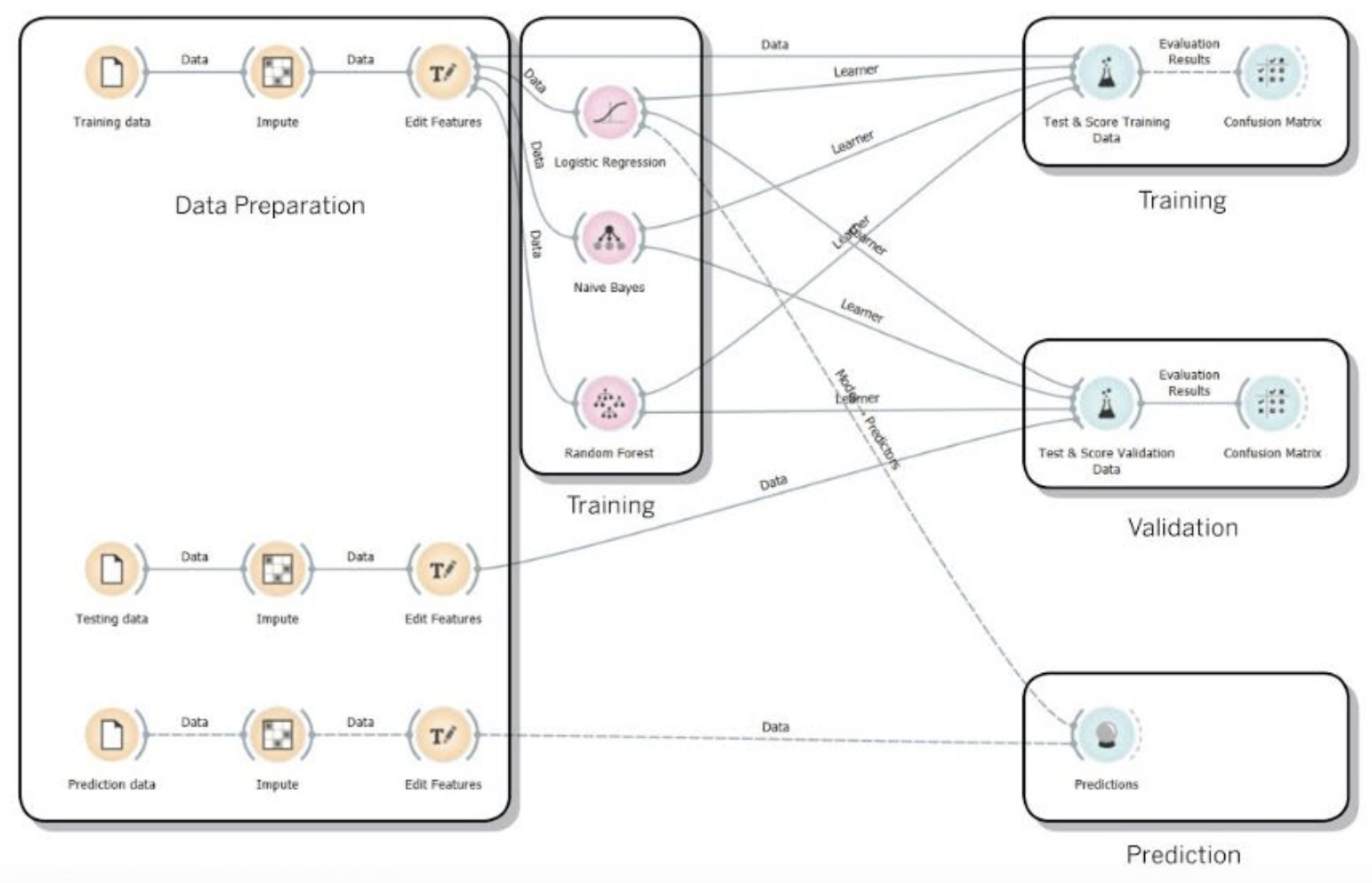
Machine Learning Models and Preliminary Result
To predict the parcels’ future development susceptibility, the City’s parcel dataset was randomly shuffled and split into three subsets: the training dataset, the testing/validation dataset, and the prediction dataset. Three different Machine Learning algorithms were trained and compared, namely, Logistic Regression, Naive Bayes, and Random Forest. Among the three, the Random Forest model had the lowest classification error. Then a separate prediction was made using the prediction dataset with the Logistic Regression model, since we were interested in explicitly tuning the subset of features that would influence the development susceptibility significantly. The modeling was implemented using Orange, an open-source data mining and analytics tool.
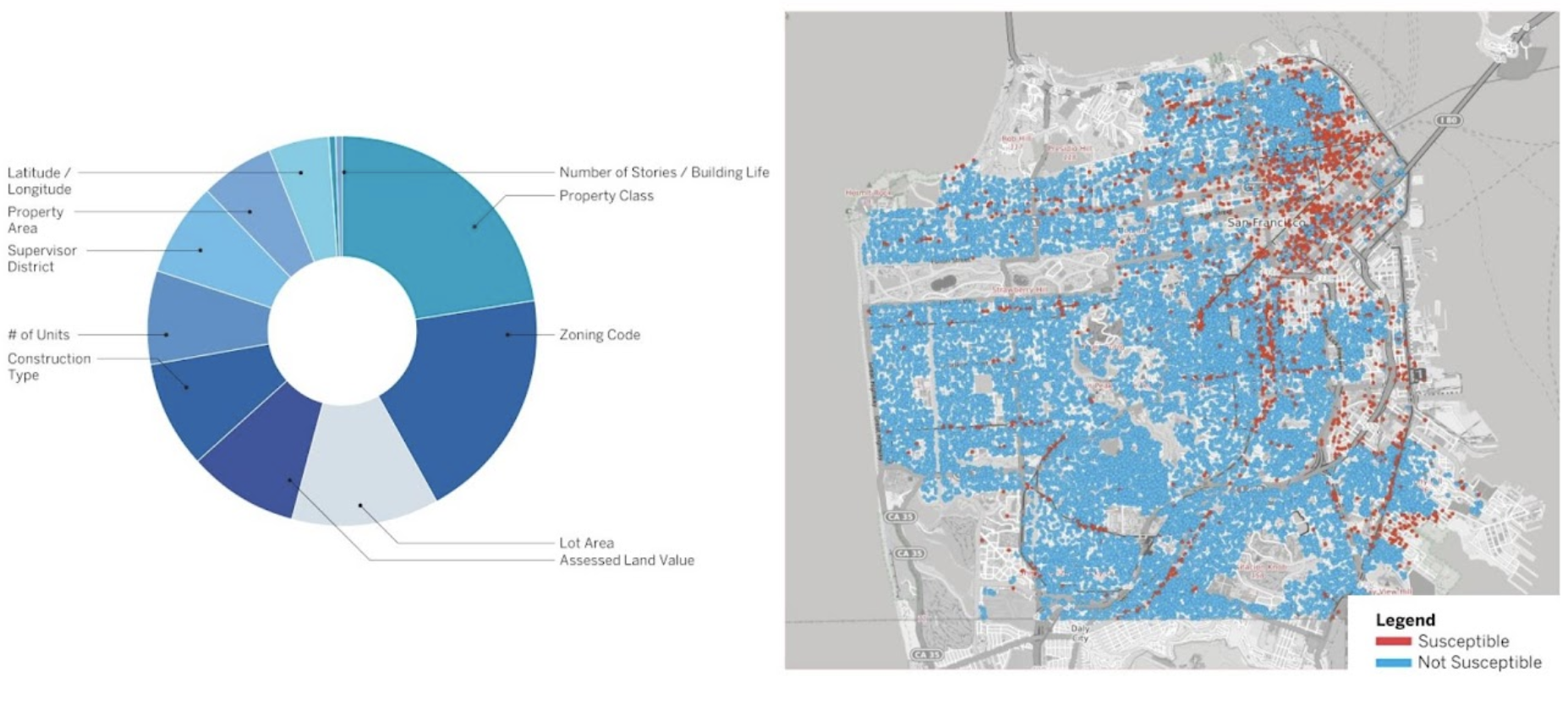
Feature Importance Ranking and Prediction Results (mapped) from the Random Forest Model
A variety of data mining and modeling tools were utilized in the analyis process, including Python, Orange, and QGIS.
Interactive Mapping Tool
Finally, the prediction results were visualized, using a combination of Mapbox Studio, Mapbox GL, and JavaScript codes, in an interactive map with customized toggles and additional layers of information for references.
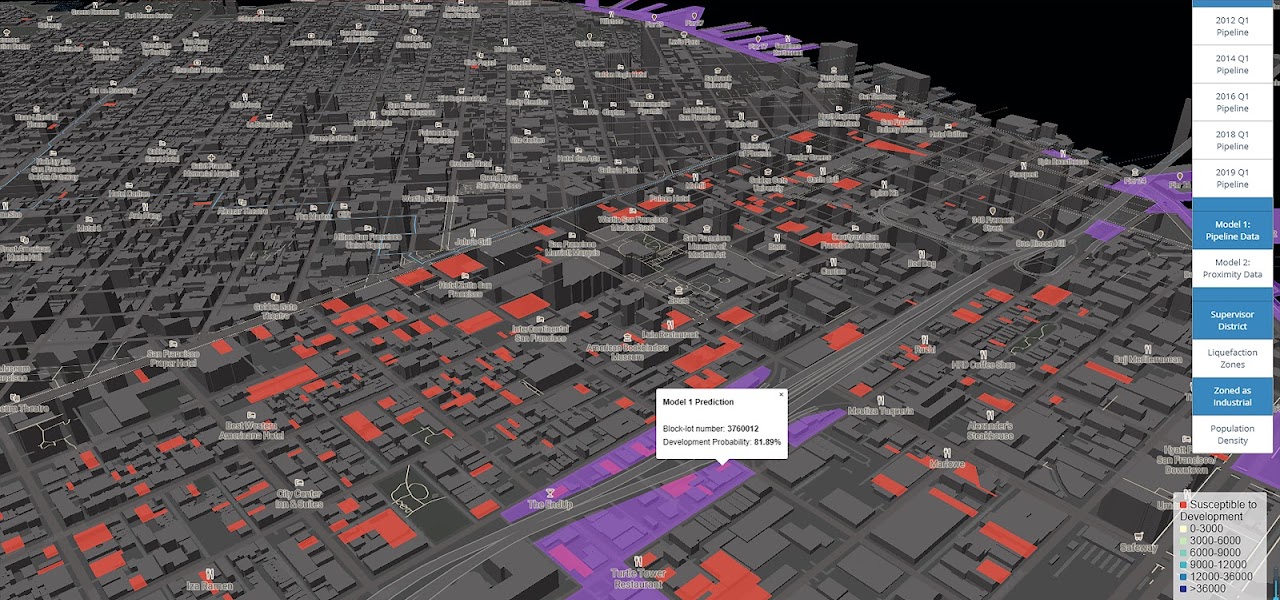
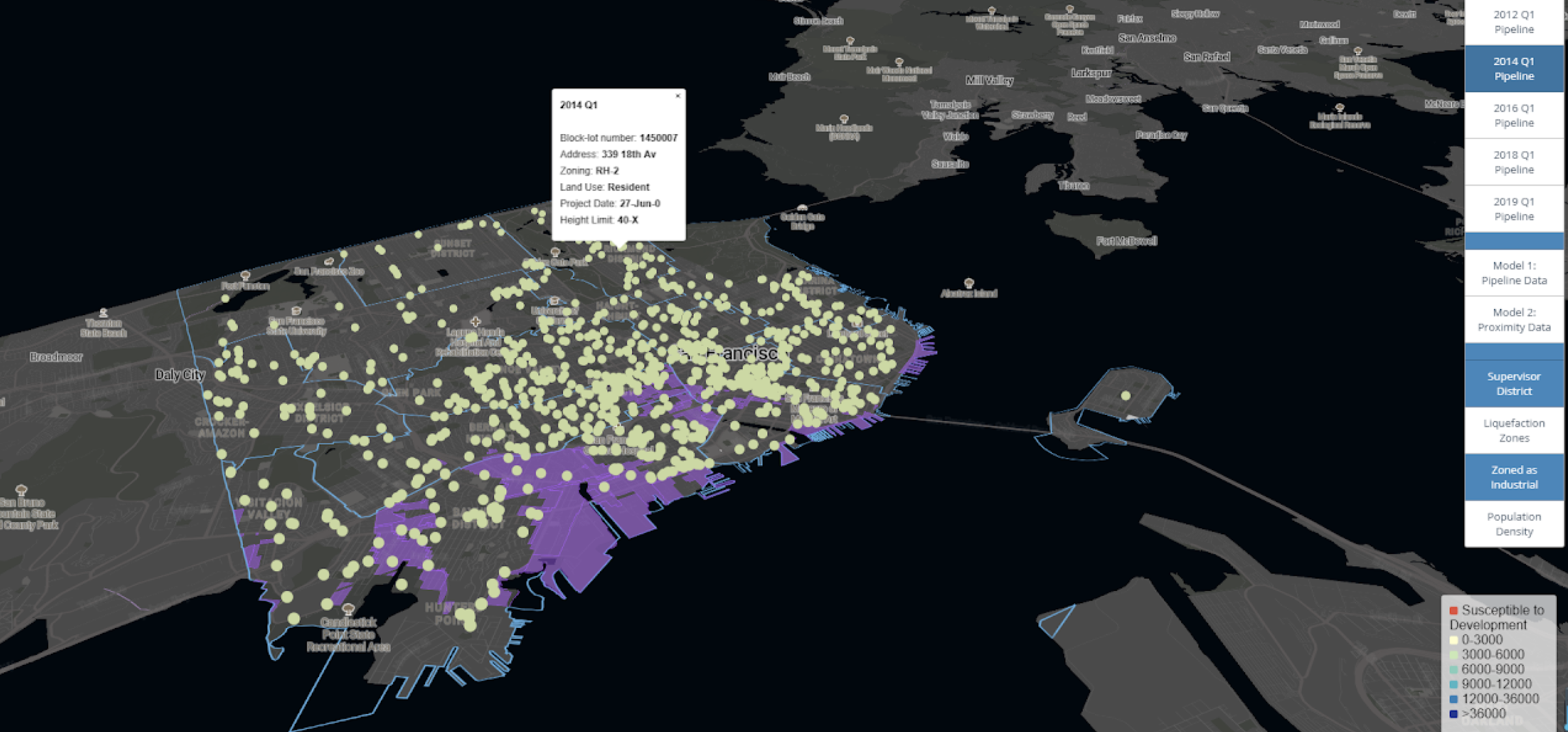
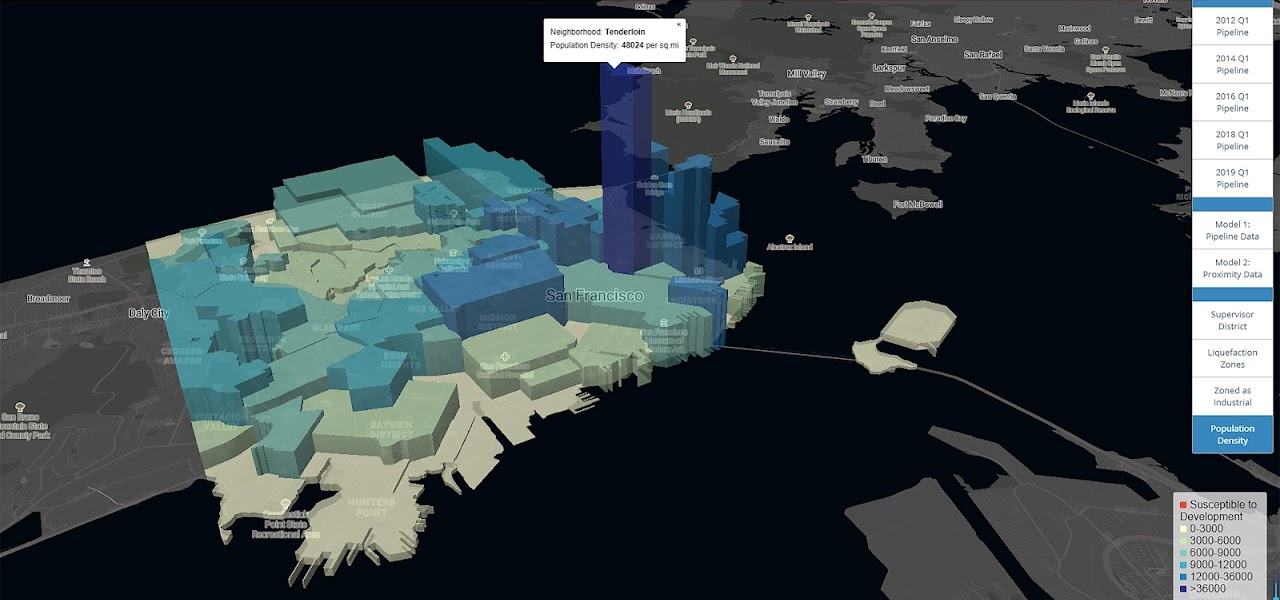
Explore the map here!